Fundamentals of modern demand forecasting
Those are two examples of don’ts in retail forecasting, but what about the dos? We’re excited to release today a new white paper that looks at the three key principles of modern forecasting for brands. They are:
- Use an integrated approach
- Keep methodology transparent
- Make results actionable
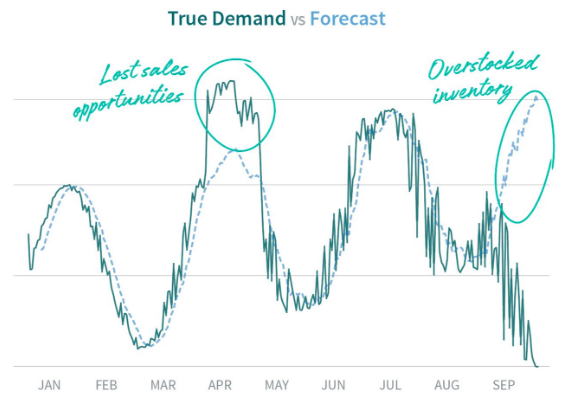
In the white paper, we cover everything from data collection to explaining model results, with a focus on maximizing the usefulness of the forecast across an organization. Gone are the days when forecasting was an early and isolated step of demand planning; to remain competitive today, brands must continually keep their forecasts up-to-date and use sound data science. And even though that data science may be mathematically complex, the components and end results of a forecast should be understandable for all business units — not just the analytics team.
In the coming weeks, we’ll explore the process of successful forecasting in greater detail. In the meantime, check out our “Fundamentals of Modern Demand Forecasting” white paper for actionable tips your company can apply to improve forecasting.