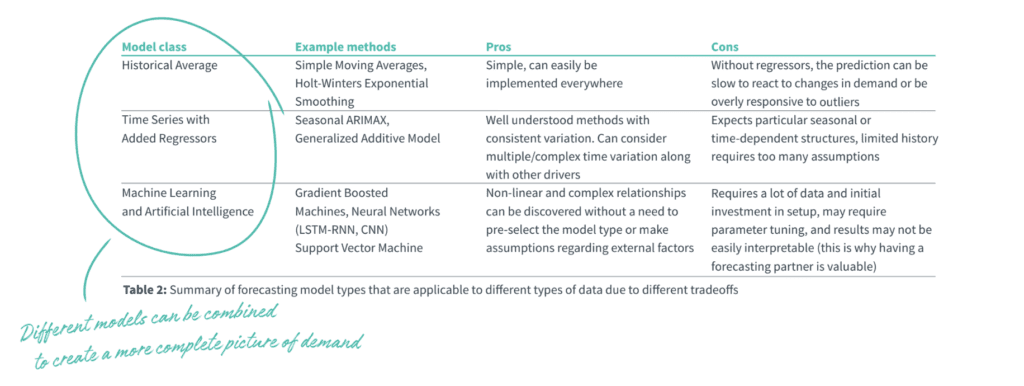
Tailoring model selection
Say you sell a machine as well as parts and supplies for that machine. Think razor and razor blades, or coffee maker and coffee pods. What demand looks like for each of these categories is probably pretty different, necessitating different algorithms. Say you further sell coffee pods with seasonal flavors in addition to your base flavors. Demand for these SKUs probably looks different too, again making different algorithms the best for each one.
The right one could also change over time. Naturally, as a product goes through its lifecycle demand patterns will shift. But it could also be the result of changes you make. For example, you might switch from doing frequent promotions to an “everyday low price” marketing strategy. This shift will likely make a different algorithm the best one for your products.
Even with today’s computing power, we don’t recommend blindly throwing every algorithm at the problem to see what emerges as the “winner.” For one, it can become a distraction. Your team gets caught up adding algorithms when they should be focused on adjusting plans based on the latest data. For another, it leads to a lack of transparency and understanding of how a forecast was created. That makes it hard to explain your demand plan, and even harder to build trust in it.
Instead, make educated decisions about which models are right for each of your products based on their characteristics, aided by technology as much as possible. Next we’ll review three different classes of commonly used modeling methods and their associated tradeoffs.